RoFormer: Enhanced Transformer with Rotary Position Embeddi
contributions
- 提出一种相对位置:旋转位置嵌入(RoPE),通过旋转矩阵编码相对位置
- 研究RoPE的特性,并表明它随相对距离的增加而衰减。之前的相对位置编码方式与线性自注意力不兼容。
- 在长文本数据集上进行测试
基于的工作
-
绝对位置编码
ft(xi,i)=Wt(xi+pi)
{pi,2tpi,2t+1=sin(k/100002t/d)=cos(k/100002t/d)
-
相对位置编码
⎩⎪⎨⎪⎧fq(xm)=Wqxmfk(xn,n)=Wk(xn+p^rk)fv(xnn)=Wv(xn+p^rk)
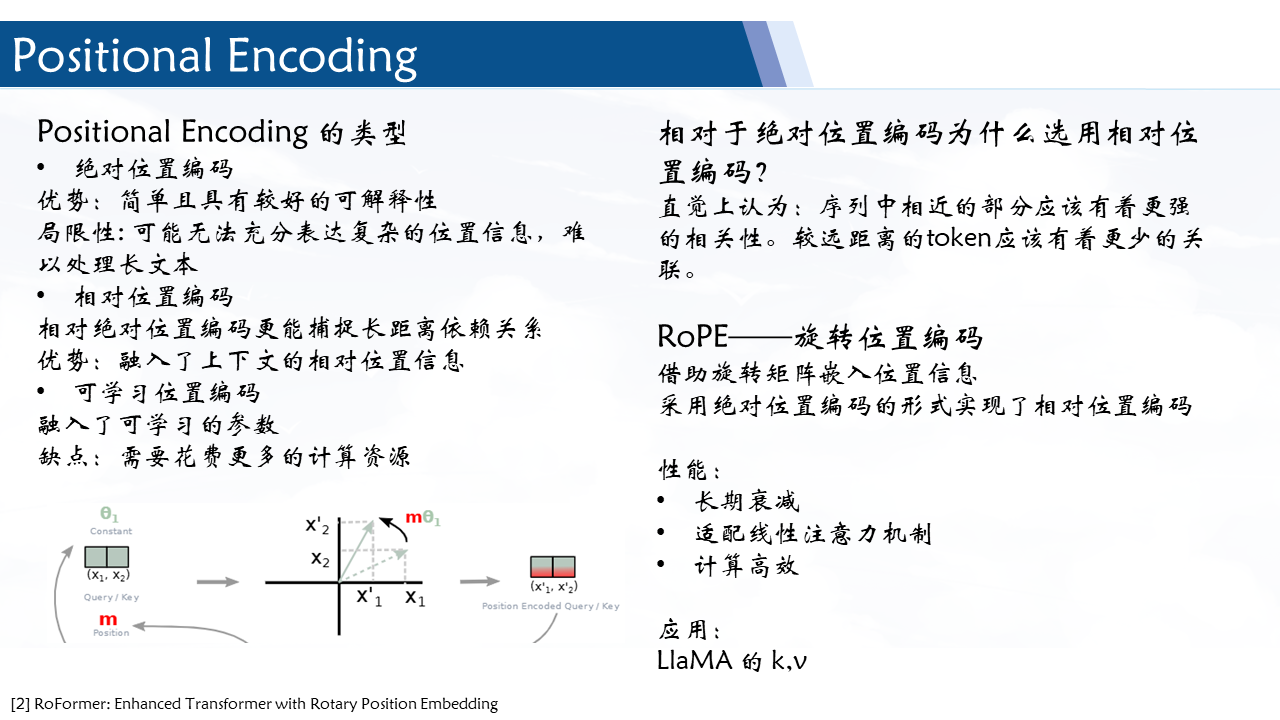
- 核心思想是将绝对位置编码的正弦项进行替换。对 k,v 添加可学习的相对位置编码,q不添加偏移量。 r 表示相对距离.
RoPE 旋转位置嵌入
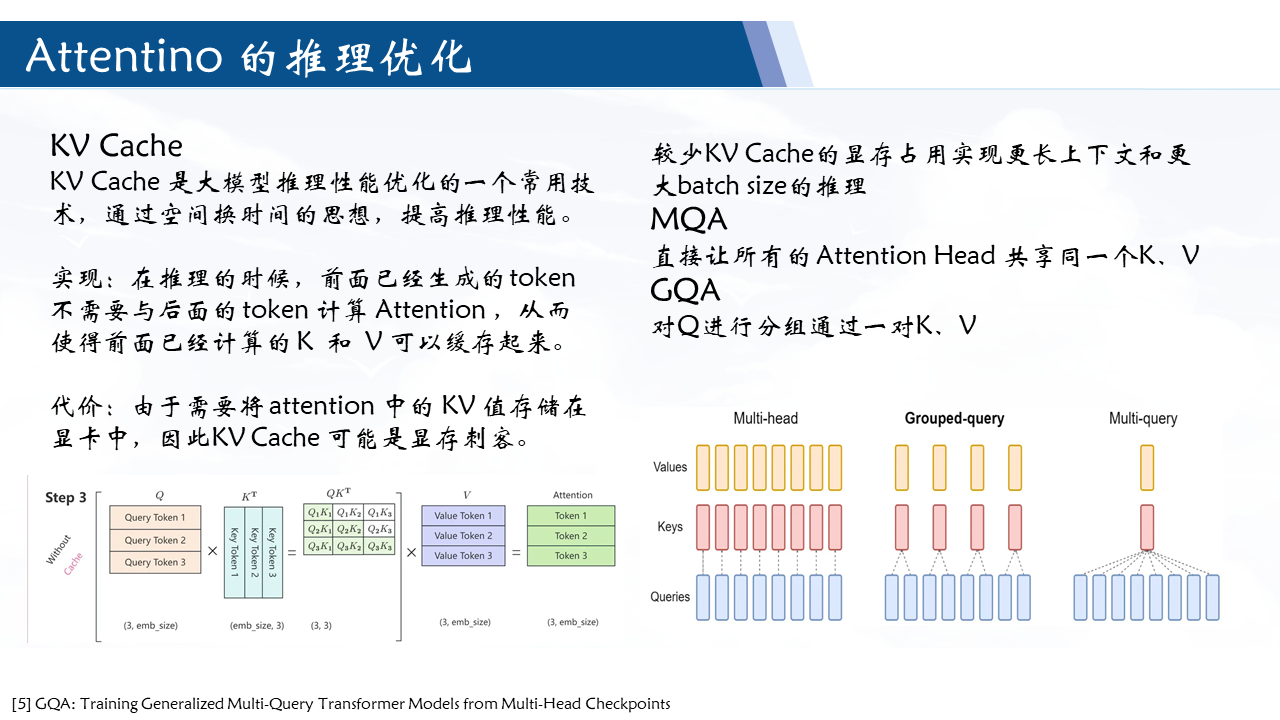
Transformer为基础的模型主要通过attention 来传递位置信息。
Attention(Q,K,V)=Softmax(dkQKT⊙M)V
由公式不难发现其通过 qmTkn 来实现不同位置 tokens 之间的信息传递。因此我们希望内积能以融入相对位置的编码信息,即:
⟨fq(xm,m),fk(xn,n)⟩=g(xm,xn,m−n)
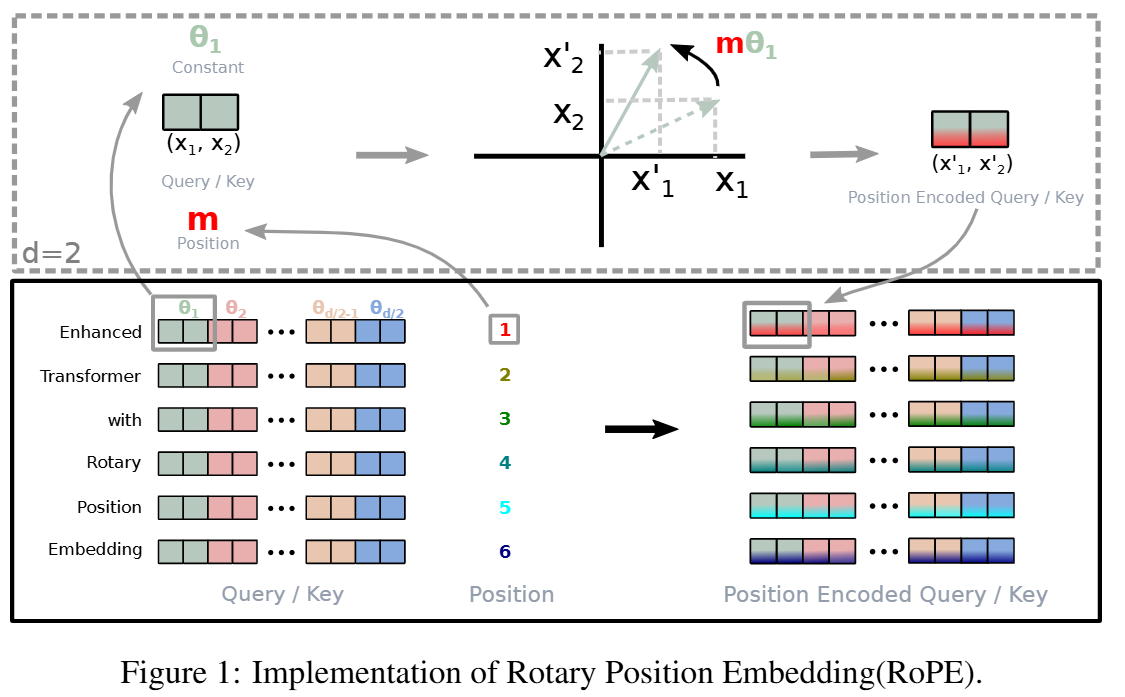
2D实现
借助复数的特性,设计编码函数
fq(xm)=(Wqxm)eimθfk(xn,n)=(Wkxm)einθg(xm,xn,m−n)=Re[(Wqxm)(Wkxm)∗ei(m−n)θ]
写为旋转矩阵的形式:
f{q,k}(xm,m)=(cosmθsinmθ−sinmθcosmθ)(W{q,k}(11)W{q,k}(21)W{q,k}(12)W{q,k}(22))(xm(2)xm(1))
拓展为一般形式
f{q,k}(xm,m)=RΘ,mdW{q,k}xm
RΘ,md=⎝⎜⎜⎜⎜⎜⎜⎛cosmθ1sinmθ100⋮00−sinmθ1cosmθ100⋮0000cosmθ2sinmθ2⋮0000−sinmθ2cosmθ2⋮00⋯⋯⋯⋯⋱⋯⋯0000⋮cosmθd/2sinmθd/20000⋮−sinmθd/2cosmθd/2⎠⎟⎟⎟⎟⎟⎟⎞
其中 d 为而偶数, Θ={θi=10000−2(i−1)/d,i∈[1,2,…,d/2]} , 应用于self-attention 可以得到:
qm⊤kn=(RΘ,mdWqxm)⊤(RΘ,ndWkxn)=x⊤WqRΘ,n−mdWkxn
使用乘法,通过旋转矩阵乘积合并相对位置信息。
特性
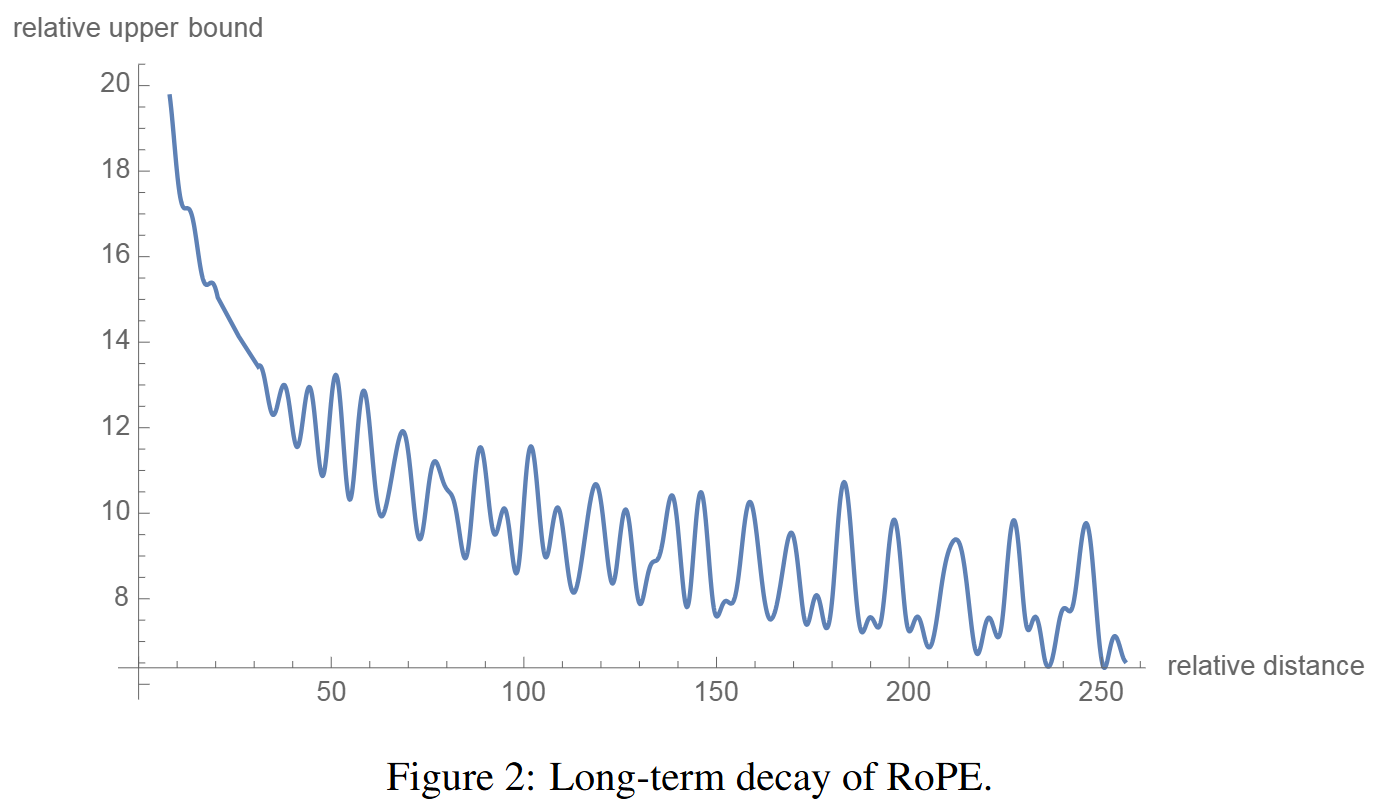
- 长期衰减:设置 θi=10000−2i/d 其提供了长期衰减的特性。随着相对距离的增加,内积会不断衰减。(更远的距离提供更少的关联)
- 具备线性注意力机制:能够将线性注意力写为更通用的形式
Attention(Q,K,V)m=∑n−1Nϕ(qm)⊤φ(kn)∑n−1Nϕ(qm)⊤φ(kn)vn⇓Attention(Q,K,V)m=∑n−1Nϕ(qm)⊤φ(kn)∑n−1N(RΘ,mdϕ(qm))⊤(RΘ,ndφ(kn))vn
ϕ(x)=φ(x)=elu(x)+1
实现更高效的计算
RΘ,mdx=⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛x1x2x3x4⋮xd−1xd⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞⊕⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛cosmθ1cosmθ1cosmθ2cosmθ2⋮cosmθd/2cosmθd/2⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞+⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛−x2x1−x4x3⋮−xdxd−1⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞⊕⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛sinmθ1sinmθ1sinmθ2sinmθ2⋮sinmθd/2sinmθd/2⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞
性能测试
- 机器翻译-blue
- 预训练-损失下降更快
- GLUE 任务
- 中文数据集——更强的长文本能力
代码实现
RoPE
Scaling Laws for Neural Language Models
L(D,N,P)≈A∗N−α+B∗D−β+C−γ
| 符号 |
含义 |
单位/类型 |
| L |
损失函数值 |
无单位(标量) |
| D |
训练数据量 |
Token 数 |
| C |
计算资源 |
FLOPs(浮点运算次数) |
| N |
模型参数规模 |
参数量(如亿、万亿) |
| α,β,γ |
原始公式的经验系数 |
|
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
contributions
- 提出 Switch Transformer 结构——对 MoE 的简化和改进
- Switch Transformer 有效性证明
- 预训练和微调技术的改进
- 选取 float16
- 运行扩展到更多专家的方案
- 增加专家正则化来改善稀疏模型的微调和多任务训练
- 多语言数据的预训练收益
- 扩大了模型的大小且提高模型的预训练速度
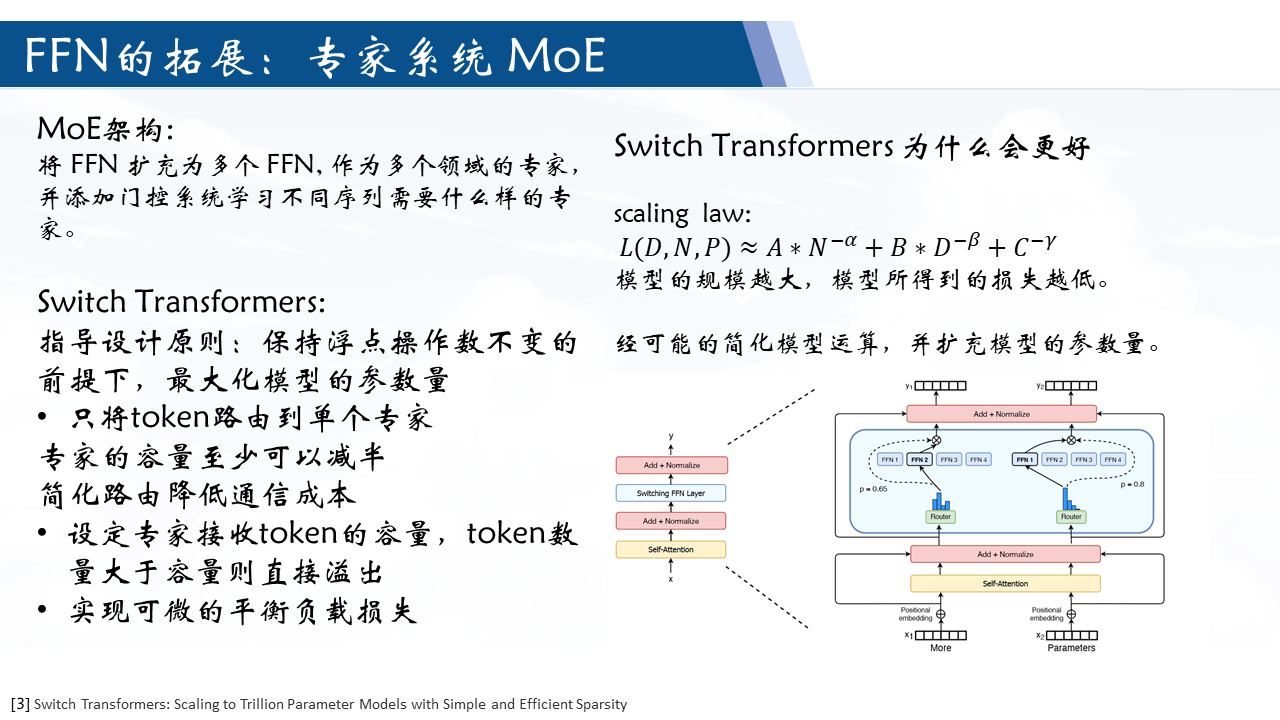
指导设计原则:最大化模型的参数量
在保持浮点操作 FLOP(运算次数)不变的前提下,增加参数的数量
在 MoE 框架下的改变:
- 只将token路由到单个专家
- 专家的容量至少可以减半
- 简化路由降低通信成本
高效稀疏路由:
专家容量=(专家数量批量大小)×容量系数
其为每个batch的tokens分配一个专家,若一个专家接收的token大于专家容量,则直接跳过计算(不通过该专家)通过残差连接进入下一层。
可微的平衡负载损失:
loss=α⋅N⋅i=1∑Nfi⋅Pi
其中 α 为超参数, N 为专家数量,
fi 为分配给专家 i 的 token 比例: fi=T1x∈B∑[argmaxp(x)=i]
Pi 为分配给专家 i 的路由的概率: Pi=T1x∈B∑pi(x)
Training and Fine-Tuning
- 在路由器输入时转化为 float32 进行计算
- 实现蒸馏
DEEPSEEKMOE
DEEPSEEKMOE: TOWARDS ULTIMATE EXPERT SPECIAL-IZATION IN MIXTURE-OF-EXPERTS LANGUAGE MODELS
MoE 架构可能遇到的问题:知识混合和知识冗余
contributions
- 架构创新:提供一种新的 MoE 架构,采用细粒度专家分割和共享专家隔离两种主要策略
- 实验验证其有效性
- 稳定性
- 与 MoE 对齐
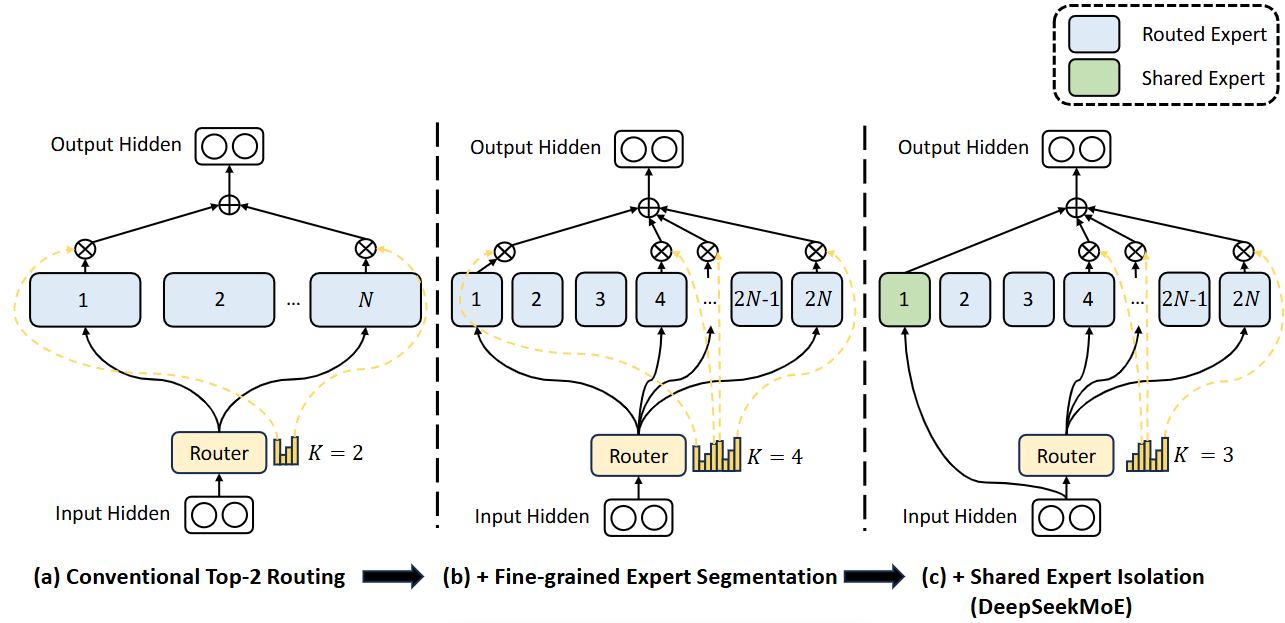
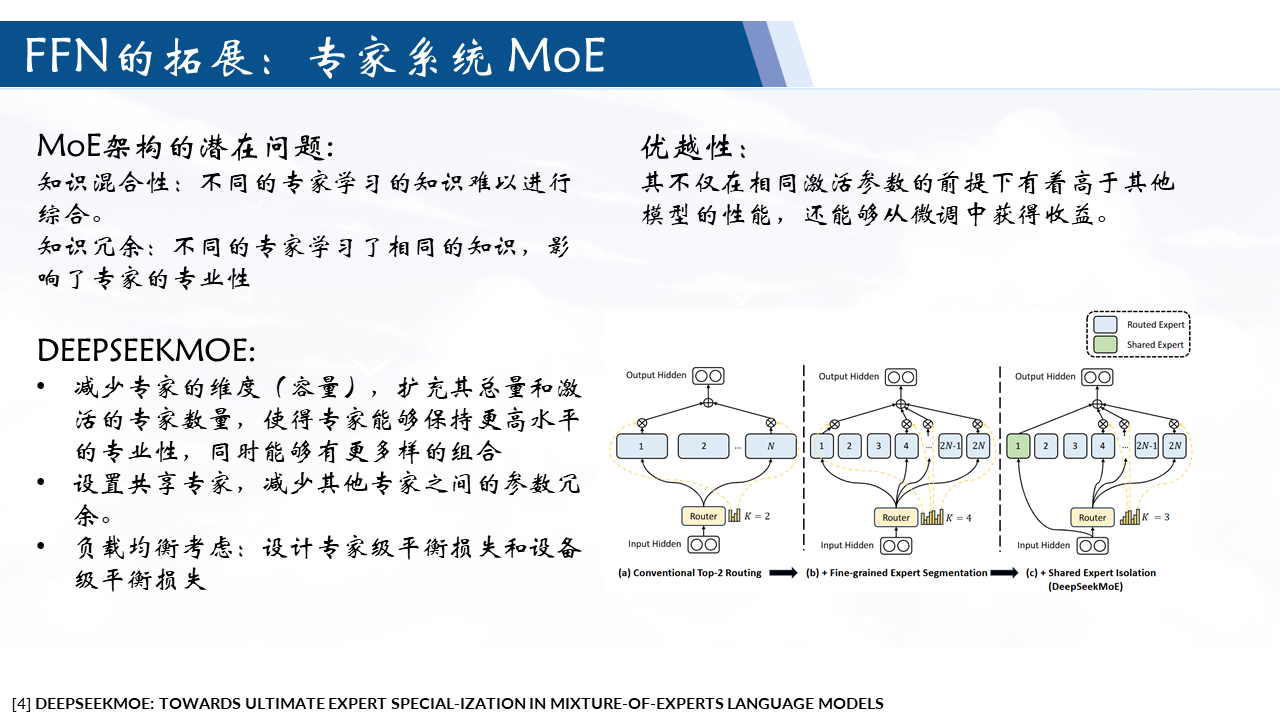
DeepSeekMoE 结构
细粒度专家细分
让不同的知识分布在不同的专家,每位专家可以保持高水平的专家专业化
做法:将专家的参数量减少,增加专家的数量和激活专家的数量。
共享专家隔离
多个专家可能会集中获取各自参数的共享知识,从而导致专家参数的冗余。
共享专家致力于捕获和巩固不同上下文中的共同知识,那么其他路由专家之间的参数冗余将会得到缓解。
做法:设定部分专家为固定的激活的专家
htl=∑i=1KsFFNi(utl)+∑i=Ks+1mN(gi,tFFNi(utl))+utl,gi,t={si,t,0,si,t∈Topk({sj,t∣Ks+1⩽j⩽mN},mK−Ks), otherwise, si,t=Softmaxi(utlTeil).
均衡负载
模型总是只选择少数专家,导致其他专家无法得到充分的训练。其次,如果专家分布在多个设备上,负载不平衡会加剧计算瓶颈。
专家级均衡损失
LExpBal fiPi=α1i=1∑N′fiPi,=K′TN′t=1∑T1( Token t selects Expert i),=T1t=1∑Tsi,t,
N′=mN−Ks, K′=mK−Ks
设备级均衡损失
LDevBal fi′Pi′=α2i=1∑Dfi′Pi′,=εi∣1j∈εi∑fi,=j∈εi∑Pj,