KV Cache
KV Cache 是大模型推理性能优化的一个常用技术,该技术可以在不影响任何计算精度的前提下,通过空间换时间的思想,提高推理性能。
KV Cache 是什么
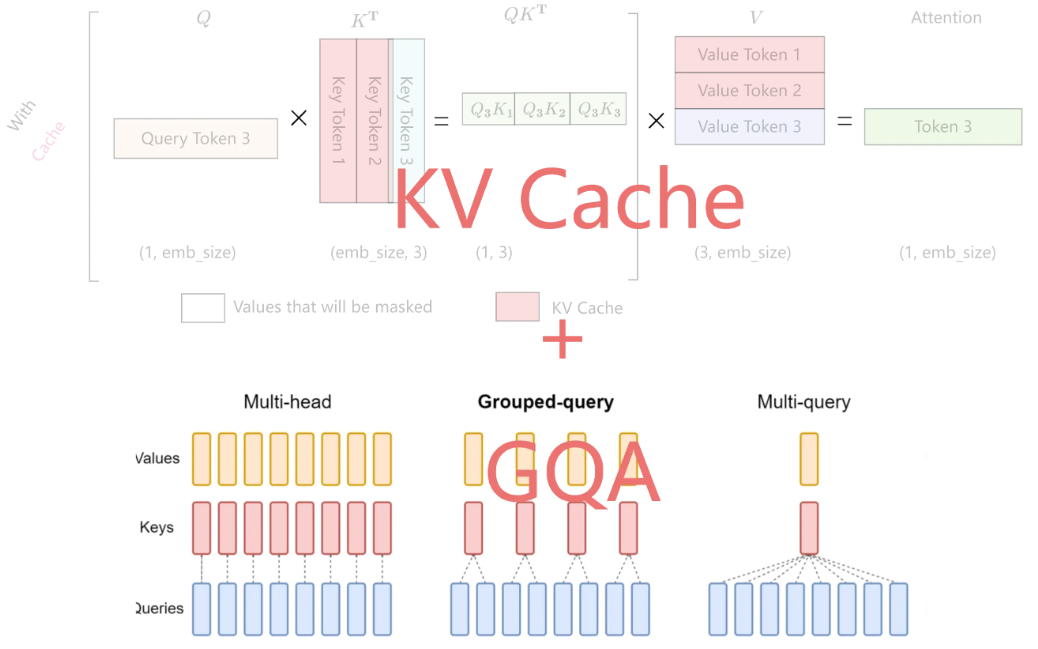
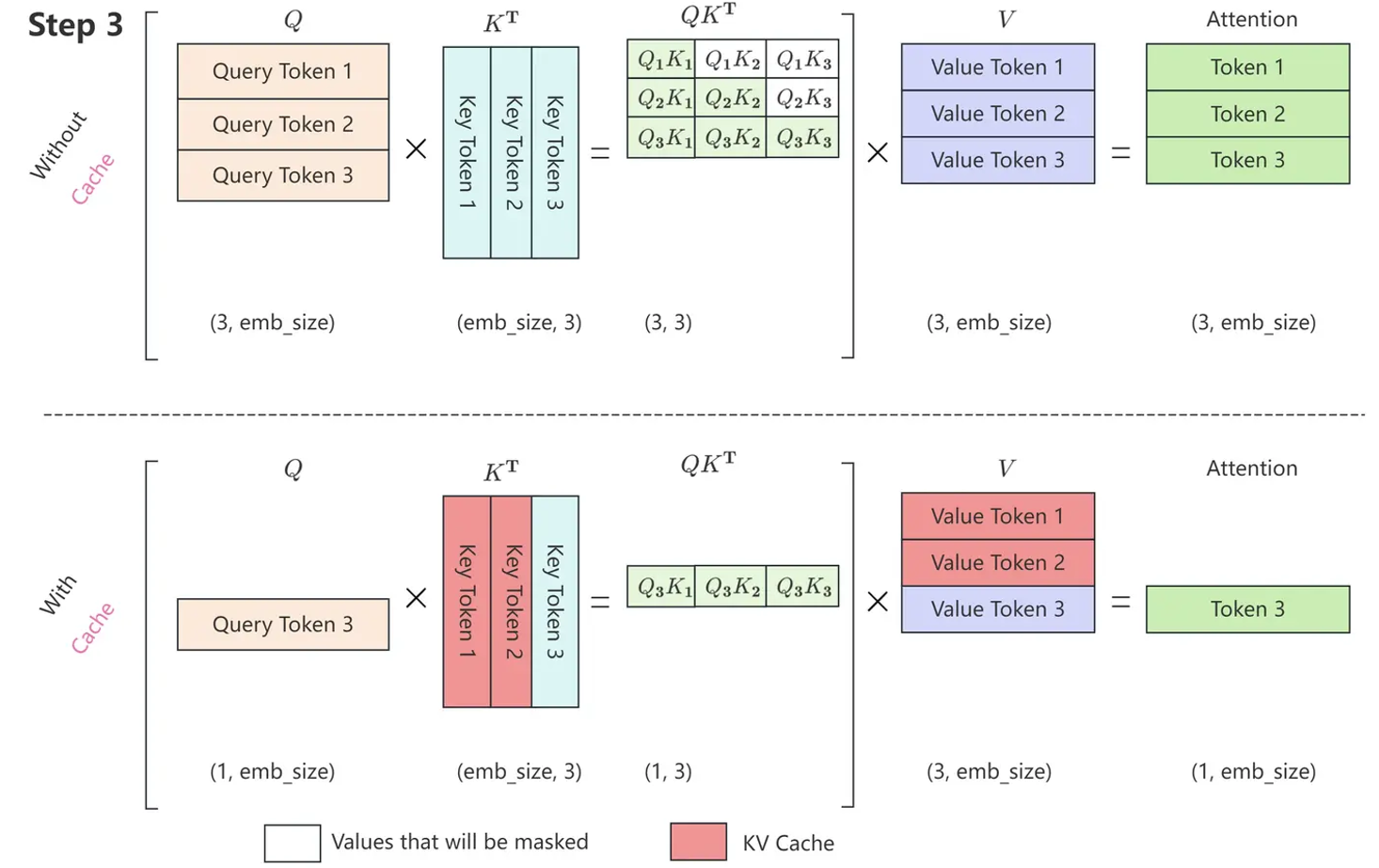
在没有KV Cache 的情况下,Attention 的计算过程如下所示。
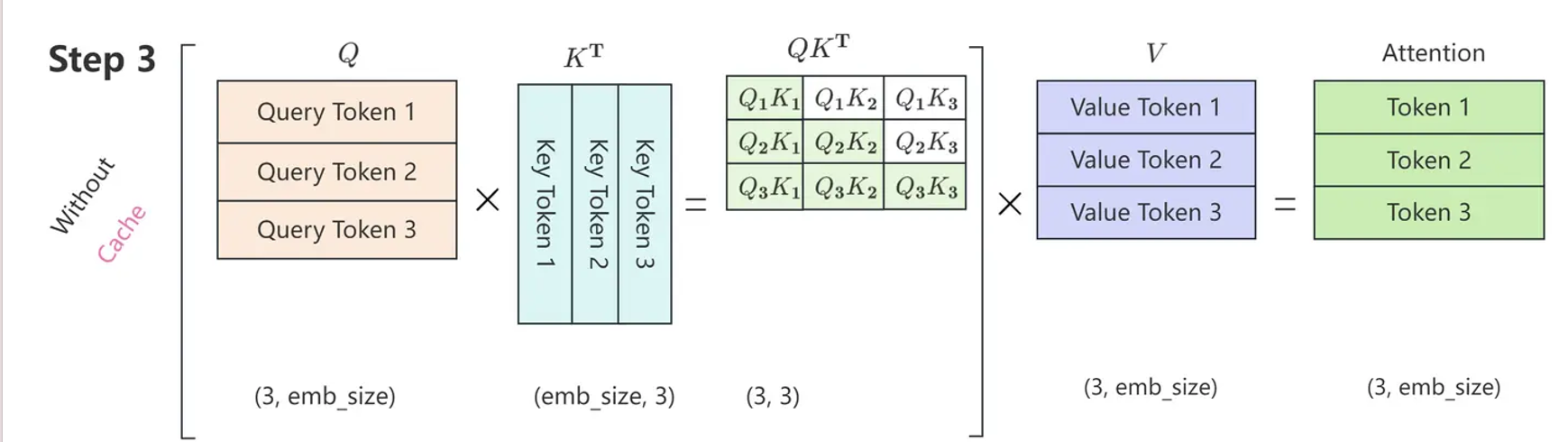
只与 有关,其公式表示如下
因此,每一步只需要根据 计算 就可以,之前已经计算好的 Attention 完全不需要重新计算。但是 和 是全程参与计算的,所以这里我们需要把每一步的 缓存起来,所以就叫KV cache。
KV Cache的实现
正是因为 Self Attention 中带 Maske,因此,在推理的时候,前面已经生成的 token 不需要与后面的 token 计算 Attention ,从而使得前面已经计算的 和 可以缓存起来。 带有 KV Cache 的推理过程包含以下两个阶段:
- 预填充阶段:输入一个 prompt 序列,为每个 transformer 层生成 Key Cache 和 Value Cache(KV cache)。
- 解码阶段:使用并更新 KV Cache,一个接一个地生成 token,当前生成的 token 依赖于之前已经生成的token。
KV Cache的代价
由于需要将 attention 中的 KV 值存储在显卡中,因此KV Cache 可能是显存刺客。
假设输入序列的长度为 ,输出序列的长度为 ,批量大小为 ,KV的高度为 , 以 float16 来保存 KV Cache,那么KV Cache 的峰值显存占用为
减小KV Cache——GQA,MQA
为实现模型在更长的上下文进行推理,提升推理效率(实现更大的batch size)。
MHA
MHA(Multi-Head Attention),也就是多头注意力,是 Transformer 中的标准 Attention 形式。在数学上,多头注意力 MHA 等价于多个独立的单头注意力的拼接。
MQA
MQA (Multi-Query Attention),2019年由 Google 在论文 Fast Transformer Decoding: One Write-Head is All You Need 中提出。
其直接让所有的 Attention Head 共享同一个
,相对于去除 的下标 ,即
使用 MQA 的模型包括 PaLM、StarCoder、Gemini 等。很明显,MQA 直接将 KV Cache 减少到了原来的 。
效果方面,目前看来大部分任务的损失都比较有限。
GQA
也有人担心 MQA 对 KV Cache 的压缩太严重,以至于会影响模型的学习效率以及最终效果。为此,一个 MHA 与 MQA 之间的过渡版本 GQA(Grouped-Query Attention)应运而生. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints。
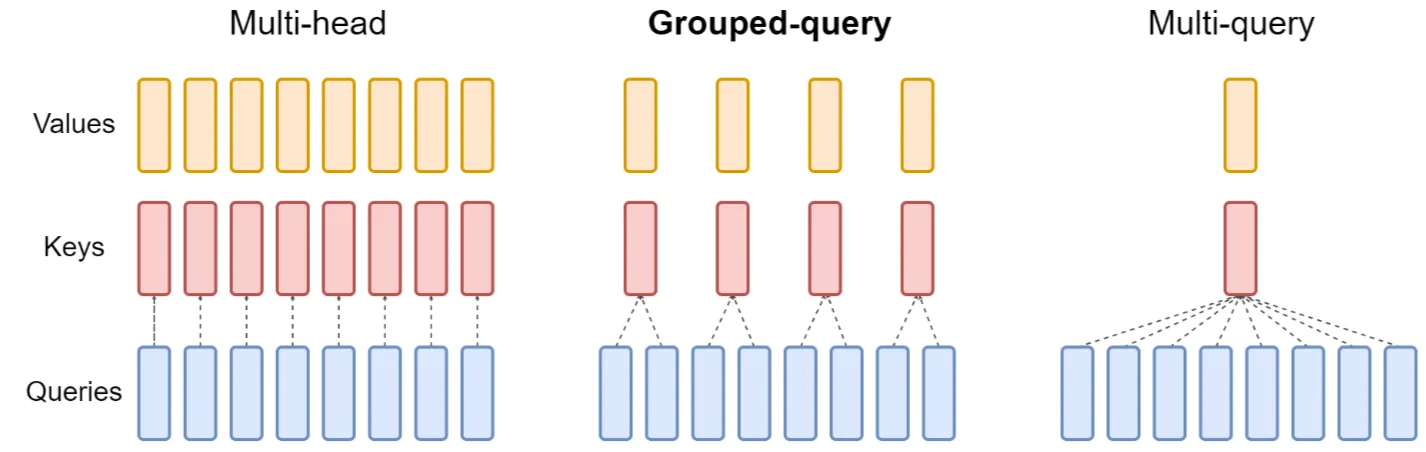
GQA 将所有 Head 分为 个组( 可以整除 ),每组共享同一对 ,用数学公式表示为
GQA 的模型包括 LLAMA2-70B,以及 LLAMA3 全系列,此外使用 GQA 的模型还有 TigerBot、DeepSeek-V1、StarCoder2、Yi、ChatGLM2、ChatGLM3、Qwen2 等,相比使用 MQA 的模型更多。
在 Llama 2/3-70B 中,GQA 的 ,其他用了 GQA 的同体量模型基本上也保持了这个设置。 原因: 70B的模型不能部署到单卡(80G)上,为了实现在单机八张卡上更高效的推理。Attention 的每个 Head 实际上是独立运算然后拼接起来的,当 时,正好可以每张卡负责计算一组 对应的 Attention Head,这样可以在尽可能保证 多样性的同时最大程度上减少卡间通信。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。



