大语言模型模块
三种类型的大语言模型:

大语言模型的正则位置、正则方法、激活函数、位置编码
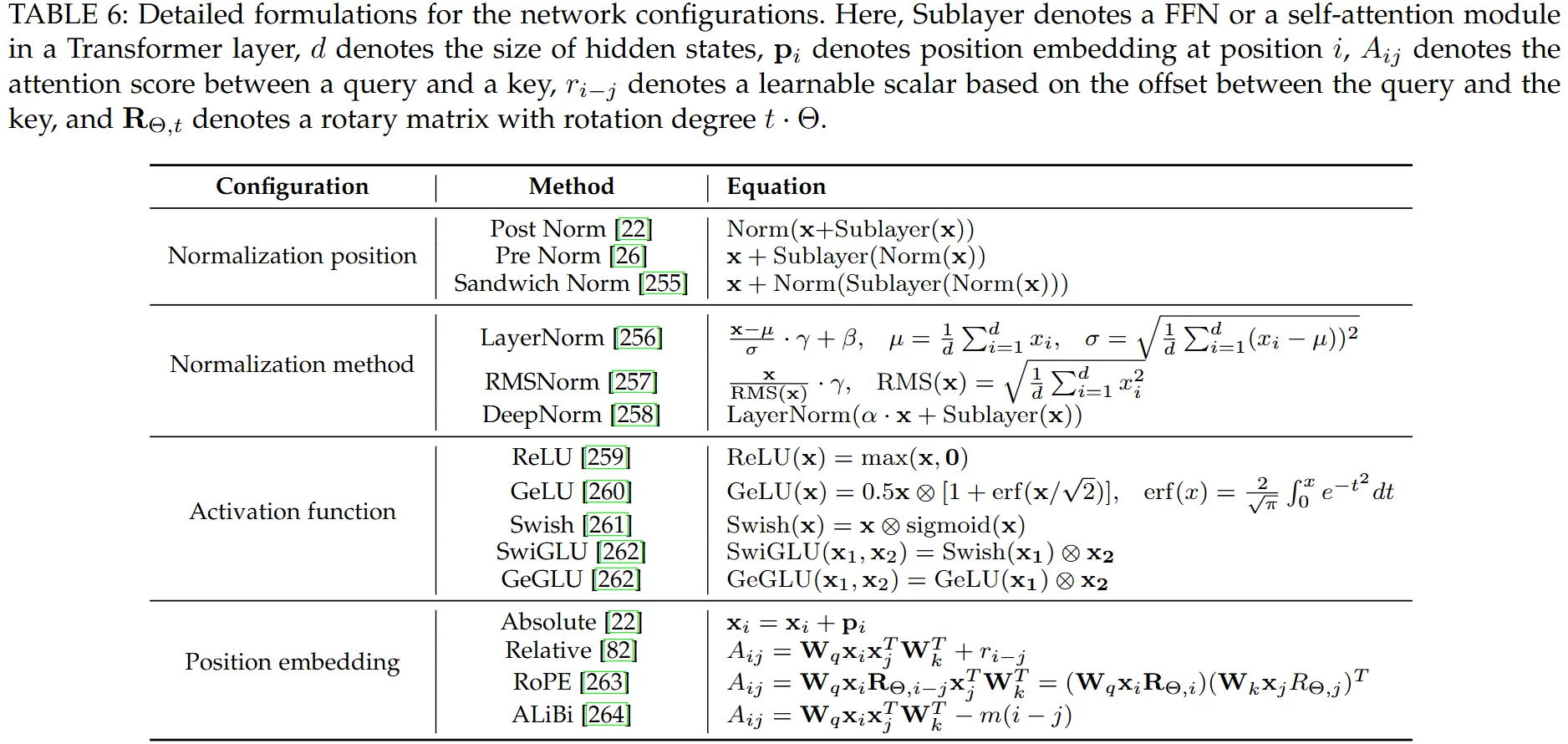
- 正则方法:
- 作用:提升神经网络训练过程的稳定性、加速收敛速度以及最终提高模型性能
- layerNorm——对单个样本的最优特征进行归一化(设定其方差和均值)
- 残差连接
- 作用:缓解了深层网络中的梯度消失和梯度爆炸问题
- 位置编码
- Absolute Position Embedding 绝对位置编码
- 直接加上正弦值获余弦值
- Relative Position Embedding 相对位置编码
- RoPE
- Content-Aware Position Embedding 内容感知位置嵌入
- Absolute Position Embedding 绝对位置编码
常见开源大语言模型
transformer
模型结构:
注意力点积和多头注意力机制
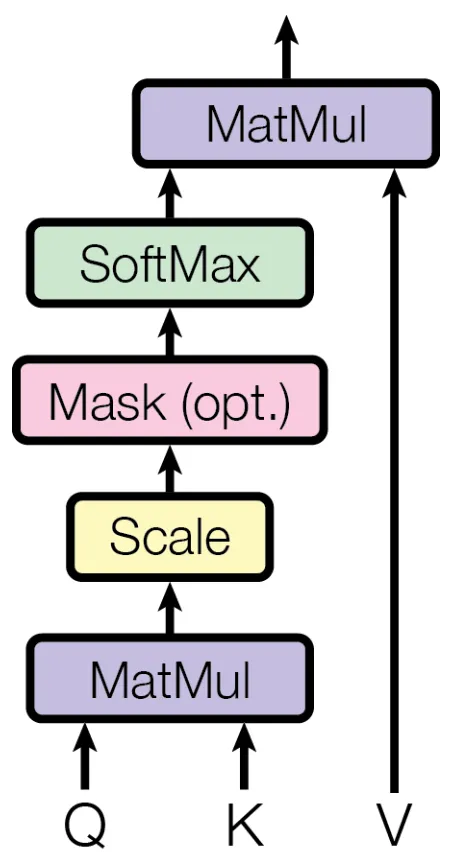
缩放点积
这里 是键向量的维度。
1、该方法通过缩放操作防止内积结果过大,防止输入softmax的值过大,导致偏导数趋近于0;
2、选择根号 是因为可以使得 的结果满足期望为0,方差为1的分布,类似于归一化。
Self-Attention 与 Cross-Attention
- Self-Attention(自注意力):当查询(Query)、键(Key)和值(Value)都来自同一个输入序列
- Cross-Attention(交叉注意力):当查询来自一个序列,而键和值来自另一个序列
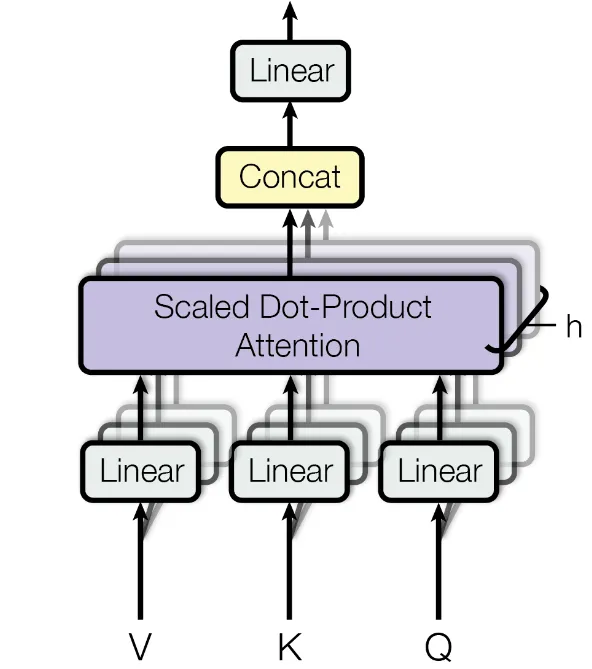
单头注意力与多头注意力
- 单头注意力(Single-Head Attention):最基础的注意力形式,直接对输入执行一次注意力计算。虽然结构简单,但其表征能力较为有限,难以捕捉输入中不同维度或语义层次的信息。
- 多头注意力(Multi-Head Attention):将输入向量分别映射到多个子空间,在每个子空间中并行执行注意力计算,最终将多个头的输出拼接融合。这种机制使得模型能从多个角度理解和关联输入中的不同部分,大幅增强了对复杂模式的建模能力。
GPT
- 使用带掩码的子注意力机制
- LayerNorm
GPT 2
- Post LayerNorm Pre LayerNorm
Llama
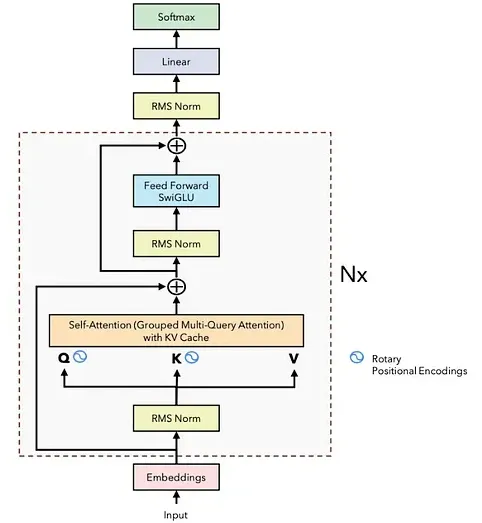
Llama 1
在原有decoder的基础上
- 使用 RMSNorm 代替 Layernorm
- 来源:LayerNorm的中心偏移没什么用(减去均值等操作)
- 增强了训练稳定性
- 提升训练速度
- 使用 SwiGLU 激活函数
- 旨在提升模型性能
- 含有一个可学习的参数 β,能够调节函数的插值程度
- 旋转式位置编码 (RoPE)——更好的建模长序列文本
- 通过正弦和余弦函数实现的绝对位置编码(Absolute Positional Embeddings)。序列中的每个位置都有其独特的编码(positional embedding),它们与词向量相加,从而确保即使单词相同,不同顺序的句子也能表达不同的意思。尽管绝对位置编码已经解决了 Transformer 不区分顺序的问题,但它生成的位置编码是相互独立的,没有考虑到序列中单词之间的相对位置关系。
- RoPE可以有效地保持位置信息的相对关系。
- RoPE 可以通过旋转矩阵来实现位置编码的外推
- RoPE 可以与线性注意力机制兼容
Llama 2
- 将序列长度
- GQA——平衡性能和准确度
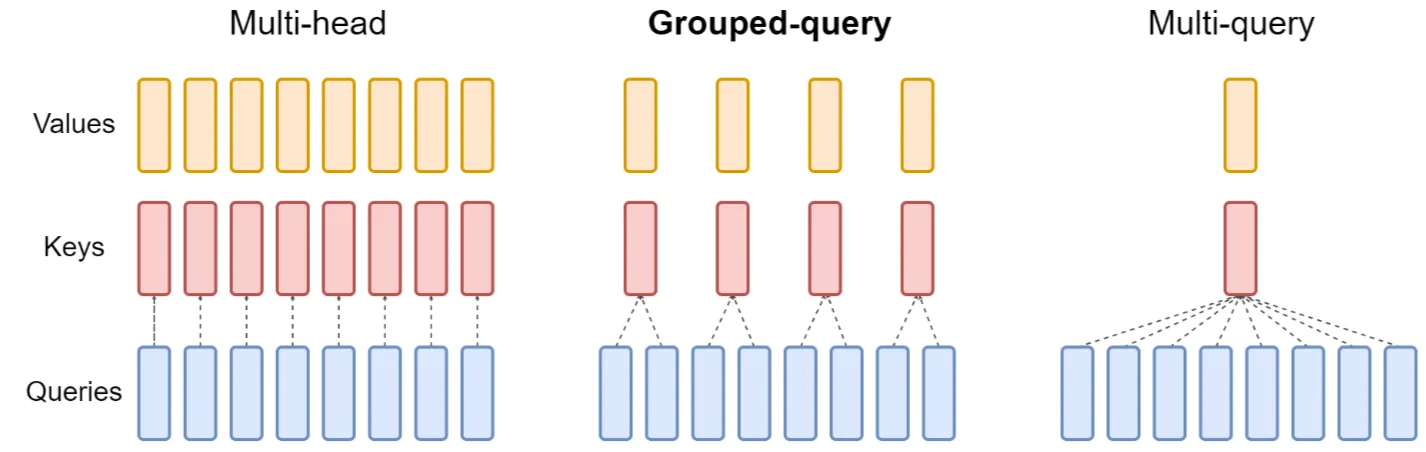
- MHA 成为了 Transformer 的性能瓶颈
- Multi-Query Attention (MQA)通过在注意力层使用单一的键和值头(key and value),配合多个查询头(query heads)来大幅降低内存需求。但这种做法可能会降低模型的质量,并导致训练过程不稳定,因此像 T5 这样的其他开源大语言模型并未采用此方法。
- GQA 则采用了一种折中方案,它将查询值(query values)分为 G 组(GQA-G),每组共享一个键和值头(key and value head)。如果 GQA 的组数为 1(GQA-1),则相当于 MQA,所有查询(queries)都集中在一组;而如果组数等于头数(GQA-H),则与 MHA 相当,每个查询(query)自成一组。这种方法减少了每个查询(query)组中的键和值头(keys and values)数量,从而缩小了键值缓存的大小,减少了需要加载的数据量。与 MQA 相比,这种更为温和的缩减方式在提升推理速度的同时,也降低了解码过程中的内存需求,且模型质量更接近 MHA,速度几乎与 MQA 持平。
Llama 3
- 上下文长度
- 分词工具 Sentence Piece TikToken , 词汇表
- 这两种分词工具的主要差异在于,在输入的 tokens 已经存在于词汇表中时,TikToken 会跳过字节对编码(BPE)的合并规则。例如,如果“generating”这个词已经在词汇表中了,那么它将作为一个完整的 token 返回,而不是将其拆分为“generating”和“ing”这两个最小单元的 tokens 。
许可协议
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。
分享文章



