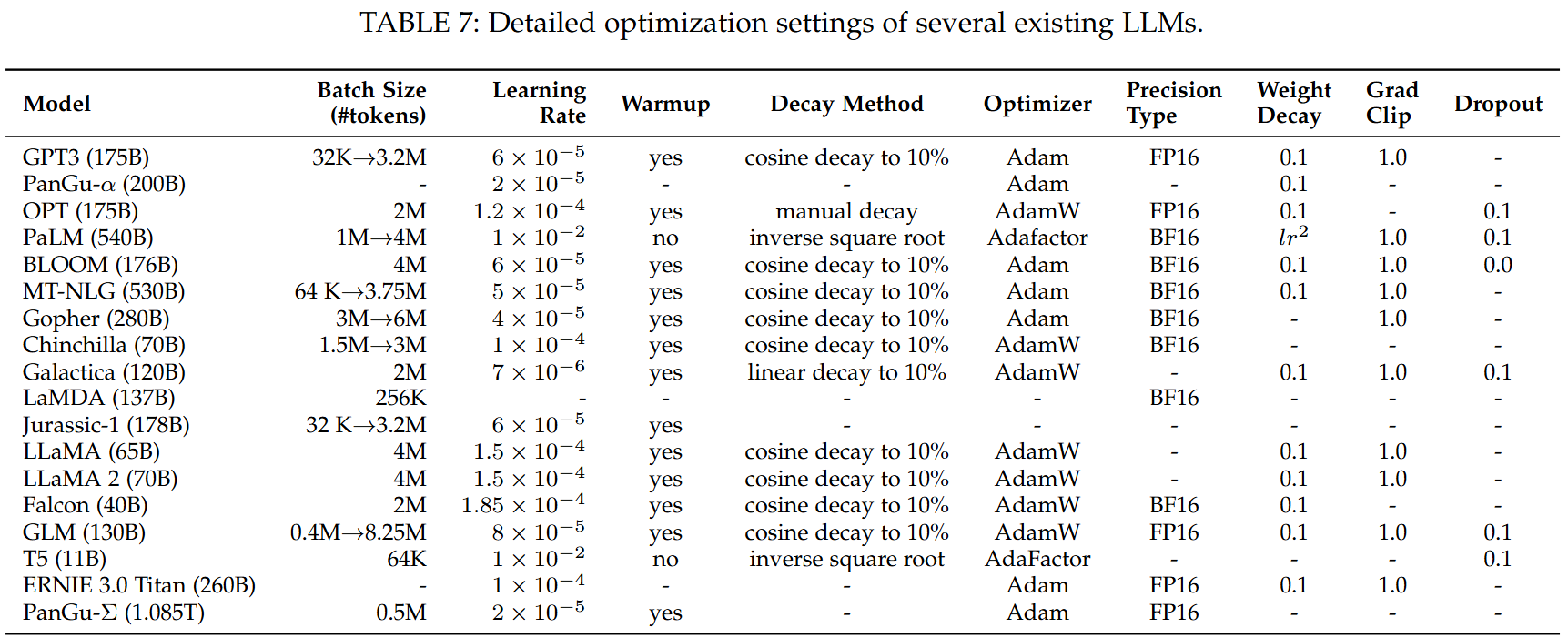
大语言模型训练超参数
批量训练 Batch Training
更大的Batch size 意味着更稳定的训练和更大的吞吐量,同时也需要更大的显存。
当然,可以使用梯度累计 (Gradient Accumulationn),在有限的显存下实习更大的Batch size
学习率 learnin rate
现有LLMs 在预训练过程中的学习率结构通常采用 warm-up + decay 的策略。
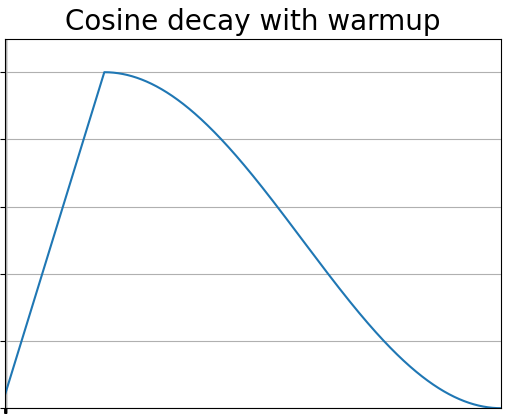
为什么要有 warm-up
由于一开始参数不稳定,梯度较大,如果此时学习率设置过大可能导致数值不稳定。使用warm up有助于减缓模型在初始阶段对 mini-batch 的提前过拟合现象,保持分布的平稳,其次也有助于保持模型深层的稳定性。
为什么要有 decay
- 缓慢降低学习率:在训练初期,学习率较高,让模型快速探索最优解。随着训练进行,学习率逐渐下降,让模型稳定收敛。
- 避免梯度震荡:相比于直接线性衰减,余弦曲线能更平稳地调整学习率,避免梯度更新过快或过慢。
梯度更新
优化器 Optimizer
优化器就是在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让损失函数(目标函数)值不断逼近全局最小。使用梯度下降进行优化,是几乎所有优化器的核心思想。
常见的优化器有:随机梯度下降SGD, Adam
权值衰减 weight decay——L2正则化系数
- 目的: 防止过拟合;保持权重在一个较小在的值,避免梯度爆炸。
梯度裁剪 Grad Clip
目的:防止梯度爆炸或梯度消失的问题,提高训练的稳定性
其他参数
Dropout
目的:使模型泛化性更强,避免过拟合
模型精度 Precision Type
类型: FP16,FP32,BF16
预训练阶段模式 (Pretrain)
3D Parallelism: DP+PP+TP
- 数据并行 DP: 将不同的训练数据放置在不同的GPU
- 流水线并行 PP:将模型不同的层放置在不同的GPU
- 张量并行 TP:将张量切片放置在不同的GPU
Zero
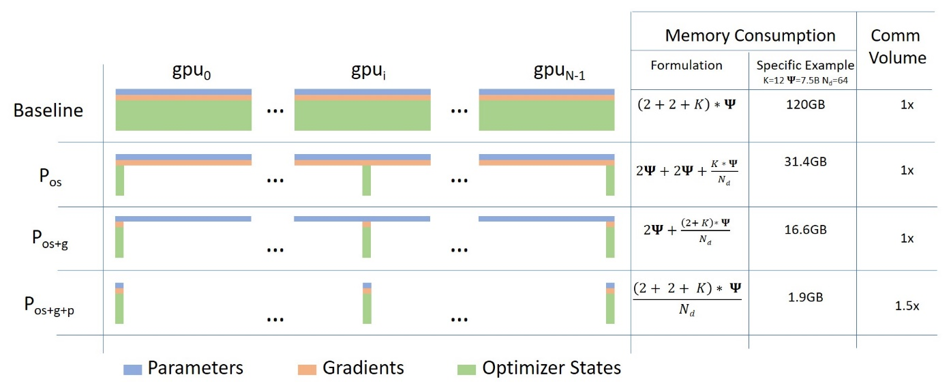
DeepSpeed库 在实现数据并行的基础上(Zero 0),对模型优化器(Zero 1)、梯度(Zero 2)、模型参数(Zero 3)进行切片进行训练。PyTorch实现了与ZeRO类似的技术,称为FSDP。
该方法降低了训练对显存的要求,但大大增加的GPU通信的时间。
混合精度训练
FP16可能会导致计算精度损失,这会影响最终的模型性能。为了缓解这种情况,采用了一种称为Brain Floating Point (BF16)的替代方案进行训练,它比FP16分配更多的指数位和更少的重要位。对于预训练,BF16在表示精度上通常比FP16表现更好。
指令微调阶段(Instruction Tuning Stage)
旨在增强llm的能力
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。



